
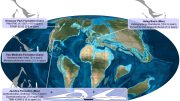
This illustration shows three possible scenarios for the evolution of asteroid belts. In the top panel, a Jupiter-size planet migrates through the asteroid belt, scattering material and inhibiting the formation of life on planets. The second scenario shows our solar-system model: a Jupiter-size planet that moves slightly inward but is just outside the asteroid belt. In the third illustration, a large planet does not migrate at all, creating a massive asteroid belt. Material from the hefty asteroid belt would bombard planets, possibly preventing life from evolving. Credit: NASA/ESA/A. Feild, STScI
A newly published study from a team of scientists suggests and explains how asteroid belts may be important both for the existence of life and perhaps even for the evolution of complex life on a planet.
Solar systems with life-bearing planets may be rare if they are dependent on the presence of asteroid belts of just the right mass, according to a study by Rebecca Martin, a NASA Sagan Fellow from the University of Colorado in Boulder, and astronomer Mario Livio of the Space Telescope Science Institute in Baltimore, Md.
They suggest that the size and location of an asteroid belt, shaped by the evolution of the sun’s protoplanetary disk and by the gravitational influence of a nearby giant Jupiter-like planet, may determine whether complex life will evolve on an Earth-like planet.
This might sound surprising because asteroids are considered a nuisance due to their potential to impact Earth and trigger mass extinctions. But an emerging view proposes that asteroid collisions with planets may provide a boost to the birth and evolution of complex life.
Asteroids may have delivered water and organic compounds to the early Earth. According to the theory of punctuated equilibrium, occasional asteroid impacts might accelerate the rate of biological evolution by disrupting a planet’s environment to the point where species must try new adaptation strategies.
The astronomers based their conclusion on an analysis of theoretical models and archival observations of extrasolar Jupiter-sized planets and debris disks around young stars. “Our study shows that only a tiny fraction of planetary systems observed to date seem to have giant planets in the right location to produce an asteroid belt of the appropriate size, offering the potential for life on a nearby rocky planet,” said Martin, the study’s lead author. “Our study suggests that our solar system may be rather special.”
The findings will appear today in the Monthly Notices of the Royal Astronomical Society.
Martin and Livio suggest that the location of an asteroid belt relative to a Jupiter-like planet is not an accident. The asteroid belt in our solar system, located between Mars and Jupiter, is a region of millions of space rocks that sits near the “snow line,” which marks the border of a cold region where volatile material such as water ice are far enough from the sun to remain intact. At the time when the giant planets in our solar system were forming, the region just beyond the snow line contained a dense mix of ices, rock and metals that provided enough material to build giant planets like Jupiter.
When Jupiter formed just beyond the snow line, its powerful gravity prevented nearby material inside its orbit from coalescing and building planets. Instead, Jupiter’s influence caused the material to collide and break apart. These fragmented rocks settled into an asteroid belt around the sun.
“To have such ideal conditions you need a giant planet like Jupiter that is just outside the asteroid belt [and] that migrated a little bit, but not through the belt,” Livio explained. “If a large planet like Jupiter migrates through the belt, it would scatter the material. If, on the other hand, a large planet did not migrate at all, that, too, is not good because the asteroid belt would be too massive. There would be so much bombardment from asteroids that life may never evolve.”
In fact, during the solar system’s infancy, the asteroid belt probably had enough material to make another Earth, but Jupiter’s presence and its small migration towards the sun caused some of the material to scatter. Today, the asteroid belt contains less than one percent of its original mass. Using our solar system as a model, Martin and Livio proposed that asteroid belts in other solar systems would always be located approximately at the snow line. To test their proposal, Martin and Livio created models of protoplanetary disks around young stars and calculated the location of the snow line in those disks based on the mass of the central star.
They then looked at all the existing space-based infrared observations from NASA’s Spitzer Space Telescope of 90 stars having warm dust, which could indicate the presence of an asteroid belt-like structure. The temperature of the warm dust was consistent with that of the snow line. “The warm dust falls right onto our calculated snow lines, so the observations are consistent with our predictions,” Martin said.
The duo then studied observations of the 520 giant planets found outside our solar system. Only 19 of them reside outside the snow line, suggesting that most of the giant planets that may have formed outside the snow line have migrated too far inward to preserve the kind of slightly-dispersed asteroid belt needed to foster enhanced evolution of life on an Earth-like planet near the belt. Apparently, less than four percent of the observed systems may actually harbor such a compact asteroid belt.
“Based on our scenario, we should concentrate our efforts to look for complex life in systems that have a giant planet outside of the snow line,” Livio said.
Reference: “On the formation and evolution of asteroid belts and their potential significance for life” by Rebecca G. Martin and Mario Livio, 27 October 2012, Monthly Notices of the Royal Astronomical Society: Letters.
DOI: 10.1093/mnrasl/sls003





According to the article, if we consider our Jupiter’s position were in a far off place in our solar system, then all inferior planets would have been only bald without any appreciable asteroidal impact, which created much desired planet chemistry to get life. Moreover the Jupiter’s right position tattered the planetary formation of nearby meteors and made them into an asteroid belt both around the Sun and also around itself. But still another bigger belt like cometary belt in our system like Kuiper belt would have done the desired thing isn’t it? If the Jupiter was still in a further inside orbit, then it would have been a binary star system, throwing all the debris around themselves in a big asteroid belt. Thank You.
I thought this was a very informational article on the significance of asteroids. I hope that you guys are doing well researching more and hope to hear about more of your research