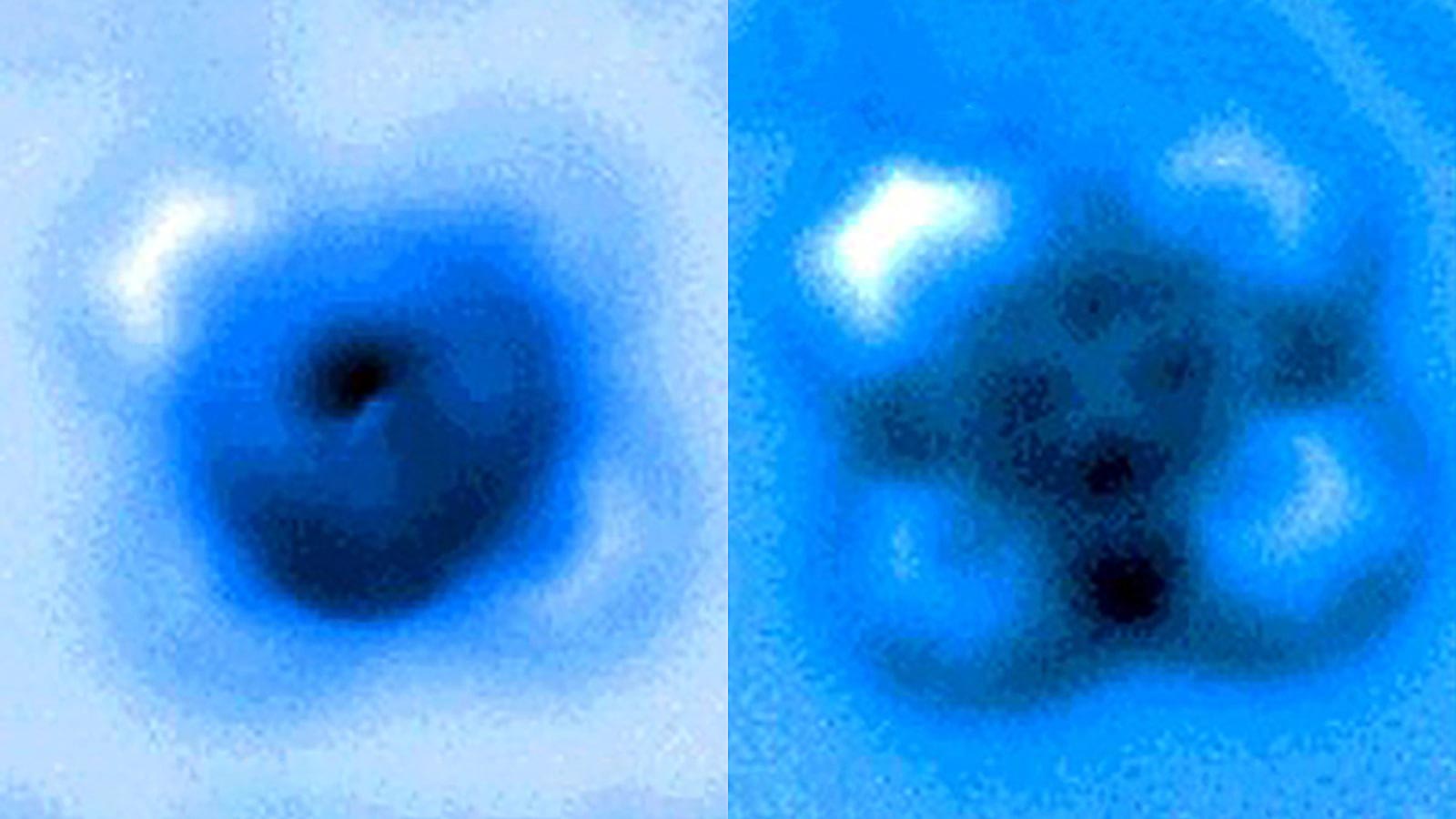
Researchers measured the mechanical forces applied to break a bond between carbon monoxide and iron phthalocyanine, which appears as a symmetrical cross in scanning probe microscope images taken before and after the bond rupture. Credit: Pengcheng Chen et al.
Using advanced microscopy techniques at Princeton University, researchers have recorded the breaking of a single chemical bond between a carbon atom and an iron atom on different molecules.
The team used a high-resolution atomic force microscope (AFM) operating in a controlled environment at Princeton’s Imaging and Analysis Center. The AFM probe, whose tip ends in a single copper atom, was moved gradually closer to the iron-carbon bond until it was ruptured. The researchers measured the mechanical forces applied at the moment of breakage, which was visible in an image captured by the microscope. A team from Princeton University, the University of Texas-Austin and ExxonMobil reported the results in a paper published on September 24, 2021, in Nature Communications.
“It’s an incredible image — being able to actually see a single small molecule on a surface with another one bonded to it is amazing,” said coauthor Craig Arnold, the Susan Dod Brown Professor of Mechanical and Aerospace Engineering and director of the Princeton Institute for the Science and Technology of Materials (PRISM).
“The fact that we could characterize that particular bond, both by pulling on it and pushing on it, allows us to understand a lot more about the nature of these kinds of bonds — their strength, how they interact — and this has all sorts of implications, particularly for catalysis, where you have a molecule on a surface and then something interacts with it and causes it to break apart,” said Arnold.
Nan Yao, a principal investigator of the study and the director of Princeton’s Imaging and Analysis Center, noted that the experiments also revealed insights into how bond breaking affects a catalyst’s interactions with the surface on which it’s adsorbed. Improving the design of chemical catalysts has relevance for biochemistry, materials science, and energy technologies, added Yao, who is also a professor of the practice and senior research scholar in PRISM.
In the experiments, the carbon atom was part of a carbon monoxide molecule and the iron atom was from iron phthalocyanine, a common pigment and chemical catalyst. Iron phthalocyanine is structured like a symmetrical cross, with a single iron atom at the center of a complex of nitrogen- and carbon-based connected rings. The iron atom interacts with the carbon of carbon monoxide, and the iron and carbon share a pair of electrons in a type of covalent bond known as a dative bond.
Yao and his colleagues used the atomic-scale probe tip of the AFM instrument to break the iron-carbon bond by precisely controlling the distance between the tip and the bonded molecules, down to increments of 5 picometers (5 billionths of a millimeter). The breakage occurred when the tip was 30 picometers above the molecules — a distance that corresponds to about one-sixth the width of a carbon atom. At this height, half of the iron phthalocyanine molecule became blurrier in the AFM image, indicating the rupture point of the chemical bond.
The researchers used a type of AFM known as non-contact, in which the microscope’s tip does not directly contact the molecules being studied, but instead uses changes in the frequency of fine-scale vibrations to construct an image of the molecules’ surface.
By measuring these frequency shifts, the researchers were also able to calculate the force needed to break the bond. A standard copper probe tip broke the iron-carbon bond with an attractive force of 150 piconewtons. With another carbon monoxide molecule attached to the tip, the bond was broken by a repulsive force of 220 piconewtons. To delve into the basis for these differences, the team used quantum simulation methods to model changes in the densities of electrons during chemical reactions.
The work takes advantage of AFM technology first advanced in 2009 to visualize single chemical bonds. The controlled breaking of a chemical bond using an AFM system has been more challenging than similar studies on bond formation.
“It is a great challenge to improve our understanding of how chemical reactions can be carried out by atom manipulation, that is, with a tip of a scanning probe microscope,” said Leo Gross, who leads the Atom and Molecule Manipulation research group at IBM Research in Zurich, and was the lead author of the 2009 study that first resolved the chemical structure of a molecule by AFM.
By breaking a particular bond with different tips that use two different mechanisms, the new study contributes to “improving our understanding and control of bond cleavage by atom manipulation. It adds to our toolbox for chemistry by atom manipulation and represents a step forward toward fabricating designed molecules of increasing complexity,” added Gross, who was not involved in the study.
The experiments are acutely sensitive to external vibrations and other confounding factors. The Imaging and Analysis Center’s specialized AFM instrument is housed in a high-vacuum environment, and the materials are cooled to a temperature of 4 Kelvin, just a few degrees above absolute zero, using liquid helium. These controlled conditions yield precise measurements by ensuring that the molecules’ energy states and interactions are affected only by the experimental manipulations.
“You need a very good, clean system because this reaction could be very complicated — with so many atoms involved, you might not know which bond you break at such a small scale,” said Yao. “The design of this system simplified the whole process and clarified the unknown” in breaking a chemical bond, he said.
Reference: “Breaking a dative bond with mechanical forces” by Pengcheng Chen, Dingxin Fan, Yunlong Zhang, Annabella Selloni, Emily A. Carter, Craig B. Arnold, David C. Dankworth, Steven P. Rucker, James R. Chelikowsky and Nan Yao, 24 September 2021, Nature Communications.
DOI: 10.1038/s41467-021-25932-6
The study’s lead authors were Pengcheng Chen, an associate research scholar at PRISM, and Dingxin Fan, a Ph.D. student at the University of Texas-Austin. In addition to Yao, other corresponding authors were Yunlong Zhang of ExxonMobil Research and Engineering Company in Annandale, New Jersey, and James R. Chelikowsky, a professor at UT Austin. Besides Arnold, other Princeton coauthors were Annabella Selloni, the David B. Jones Professor of Chemistry, and Emily Carter, the Gerhard R. Andlinger ’52 Professor in Energy and the Environment. Other coauthors from ExxonMobil were David Dankworth and Steven Rucker.
This work was supported in part by ExxonMobil through its membership in the Princeton E-ffiliates Partnership of the Andlinger Center for Energy and the Environment. Princeton University’s Imaging and Analysis Center is supported in part by the Princeton Center for Complex Materials, a National Science Foundation Materials Research Science and Engineering Center. Additional support was provided by the Welch Foundation and the U.S. Department of Energy.







This is insane!!!!!
Cool (literary).