
An event recorded during 2016 with the CMS detector that contains 10 jets (orange cones) and a muon (red line). Credit: CMS Collaboration
The standard model of particle physics encapsulates our current knowledge of elementary particles and their interactions. However, the standard model is not complete; for example, it does not describe observations such as gravity, has no prediction for dark matter, which makes up most of the matter in the universe, or that neutrinos have mass.
To fix the standard model’s weaknesses, physicists propose extensions and check the collisions at the LHC to see if predictions of those models of “physics beyond the standard model” would show up as new particles or changes in the behavior of known particles. Supersymmetry, or SUSY for short, is one of those extensions of the standard model. Supersymmetry predicts that every known particle type in the standard model has a supersymmetric partner. The number of particle types in nature would then be effectively doubled, and many new interactions between the regular particles and the new SUSY particles would be possible.
At a collider experiment like CMS, the hope is to produce some SUSY particles and then look for signs of their decay inside the detector. One of the most common signatures for supersymmetry would be measured as seemingly missing particles that create a substantial energy imbalance in the detector called missing transverse energy. This is a final-state signature that is hard to miss!
Many searches have taken place at CMS to look for these high missing transverse energy signatures, but no such evidence for supersymmetry has been found. But, perhaps supersymmetry is there, and it is just “stealthier” than initially thought. There are many different possible signatures that supersymmetry could create, and in some modified versions of supersymmetry, a key feature is the prediction that all SUSY particles would decay back into standard model particles, for example, quarks, each of which would appear in the detector as a spray of particles, which is called a jet. If this version of supersymmetry is real, SUSY particles’ production in a proton-proton collision will result in a final state with many jets rather than one with considerable missing energy. In this case, it would make sense why these previous searches have not found anything!
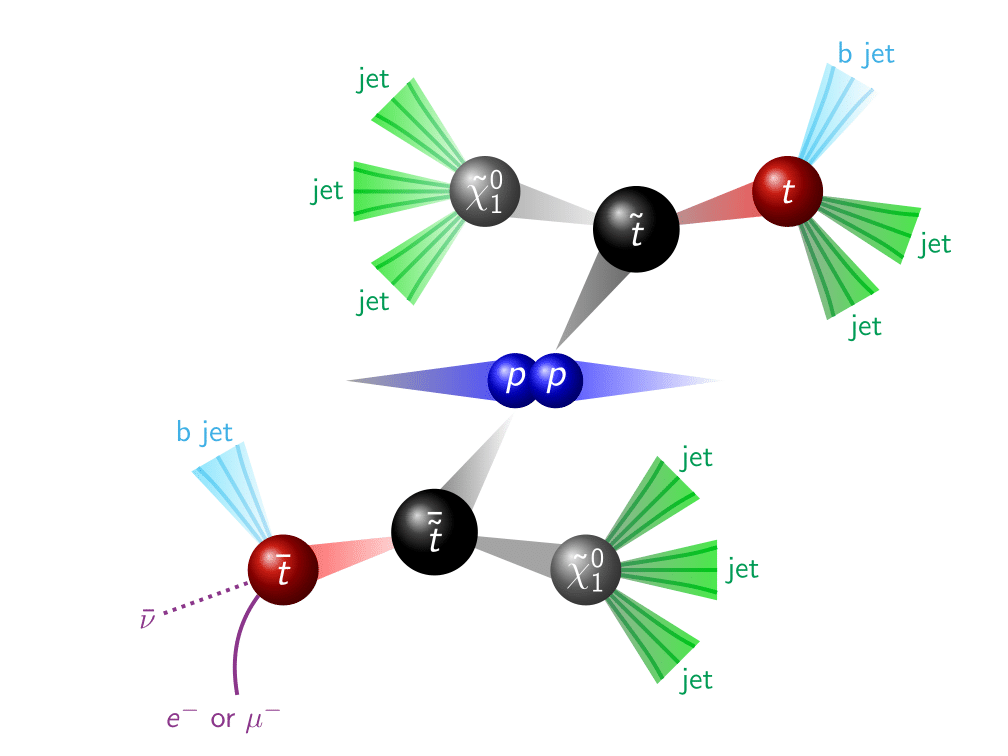
Figure 1. A dramatization of a proton-proton collision producing SUSY particles, which decay to objects observed in the detector (this is a signature for so-called R-parity violating SUSY). Credit: CMS Collaboration
The goal of this search is to find out whether or not supersymmetry has been hiding there all along by specifically looking for the production of two supersymmetric top quarks (called top squarks). These top squarks decay in the detector, creating two top quarks and many other jets, as shown in Figure 1. This signature is not as apparent as one that includes large amounts of missing energy since there are many different ways the standard model can produce two top quarks and lots of jets. However, this top squark signal tends to make more jets on average than any of the known background processes. The modeling of events with a very large number of jets is also very tricky, and even the best simulation tools do not always get it right. Therefore, data is relied on to predict the number of events with a certain number of jets.
Our strategy would not have been possible without harnessing the power of machine learning and neural networks. A cool machine learning technique that was used to identify collisions that might contain the decays of top squarks is called gradient reversal, which can be explained in the following way. Imagine you are sorting chocolates into two categories: chocolates with caramel and regular chocolates. You know that caramel chocolates are heavier than regular chocolates because they are filled with caramel. Let’s also say that the chocolates only come in two shapes among all the caramel and regular varieties: squares or circles. Finally, you are told that the square chocolates are, on average, heavier than the circular ones.
One way to sort the chocolates is to sort all of the square chocolates as caramel chocolates and all the circular chocolates as regular chocolates. After all, both square chocolates and caramel chocolates are in general heavier. This sorting approach is not correct because not all square chocolates have caramel in them, so it is probably better to sort the chocolates independently of their shape. Ignoring shape when sorting is equivalent to what gradient reversal allows us to do in the physics context. Instead of caramel and regular chocolates, the sorting is between signal and background events, and instead of shape, the sorting should be independent of the number of jets.
This strategy is precisely what is needed to model the distribution of the number of jets directly from the data. Events in the background category are used to predict how many events there should be with a certain number of jets in the signal category. Since the signal model tends to produce more jets than the standard model backgrounds, any deviations from the prediction could mean that there was indeed some SUSY hiding there.
Figure 2 shows a comparison of the number of jets distribution obtained from the collected data with that from our final background prediction. In this case, the prediction assumes there is no contribution from our hypothesized signal models. Here, the agreement between data and our prediction from four categories of standard model processes is reasonably good.

Figure 2. The distribution of the number of events with a certain number of jets is shown for the collected data (black points) and the predicted contributions from known standard model backgrounds (colored blocks). Different colored/styled lines show the number of jets distribution for different SUSY models with specific top squark masses. Credit: CMS Collaboration
When the data are broken down into more categories than shown in Figure 2, a small deviation from our prediction is found. However, the deviation is not large enough to make a strong claim about whether or not this indicates that supersymmetry might be correct. It is most likely that there was just a statistical fluctuation in the data, or perhaps that there is an unknown modeling issue.
In particle physics, the “gold standard” is to declare a discovery of new physics when a result has a significance of 5 standard deviations or greater. This means there is only a 1 in 3.5 million chance that the result is just from a random fluctuation in data. Evidence, or claiming that something is interesting enough to consider the possibility that it might be new, is only done with a significance of 3 standard deviations, representing a 1 in 740 chance that the result is a fluctuation. This standard is very stringent compared to most other scientific disciplines. The LHC produces a massive amount of data, so it can indeed happen that a deviation from the standard model prediction is obtained just by random chance. In particle physics, it is definitely not warranted to claim any deviation without seriously examining its statistical validity.
The significance of the largest deviation that was observed in this analysis, without correction for the look elsewhere effect, is 2.8 standard deviations. This means that even if there is no supersymmetry, one expects to see such a result once every 368 times, well below the 5 standard deviation threshold. Given that CMS has published more than 1000 papers, many looking in tens or hundreds of places, you can see that an occasional fluctuation in one result is not at all surprising. The results can also be interpreted as a limit on the allowed stealthy supersymmetry scenarios that are still consistent with the data. Depending on the details of the model, top squark masses below ~700 GeV can be excluded.
This search is the first of its kind at the LHC, shedding light on a previously unexplored signature. The slight discrepancy found is tantalizing and prompts follow-up studies to investigate whether its origin is a simple statistical fluctuation, whether it is due to our understanding of the Standard Model, which would be interesting in its own right, or whether it could be the first sign of new physics. Also, starting in 2022, the next data-taking period of the LHC will start. This will help CMS make even stronger conclusions about the possibility of new physics. If stealthy supersymmetry really is there, then this extra data would allow for a more significant result, potentially pushing towards the gold standard for discovery.








…could gravity be compared to the convection, rather than other forces…