
The giant squid is an elusive giant, but its secrets are about to be revealed. A new study led by the University of Copenhagen has sequenced the creature’s entire genome, offering an opportunity to throw some light on its life in the depths of the sea.
Sailors’ yarns about the Kraken, a giant sea monster lurking in the abyss, may have an element of truth.
“Our initial genetic analysis generated more questions than it answered.” Professor Tom Gilbert
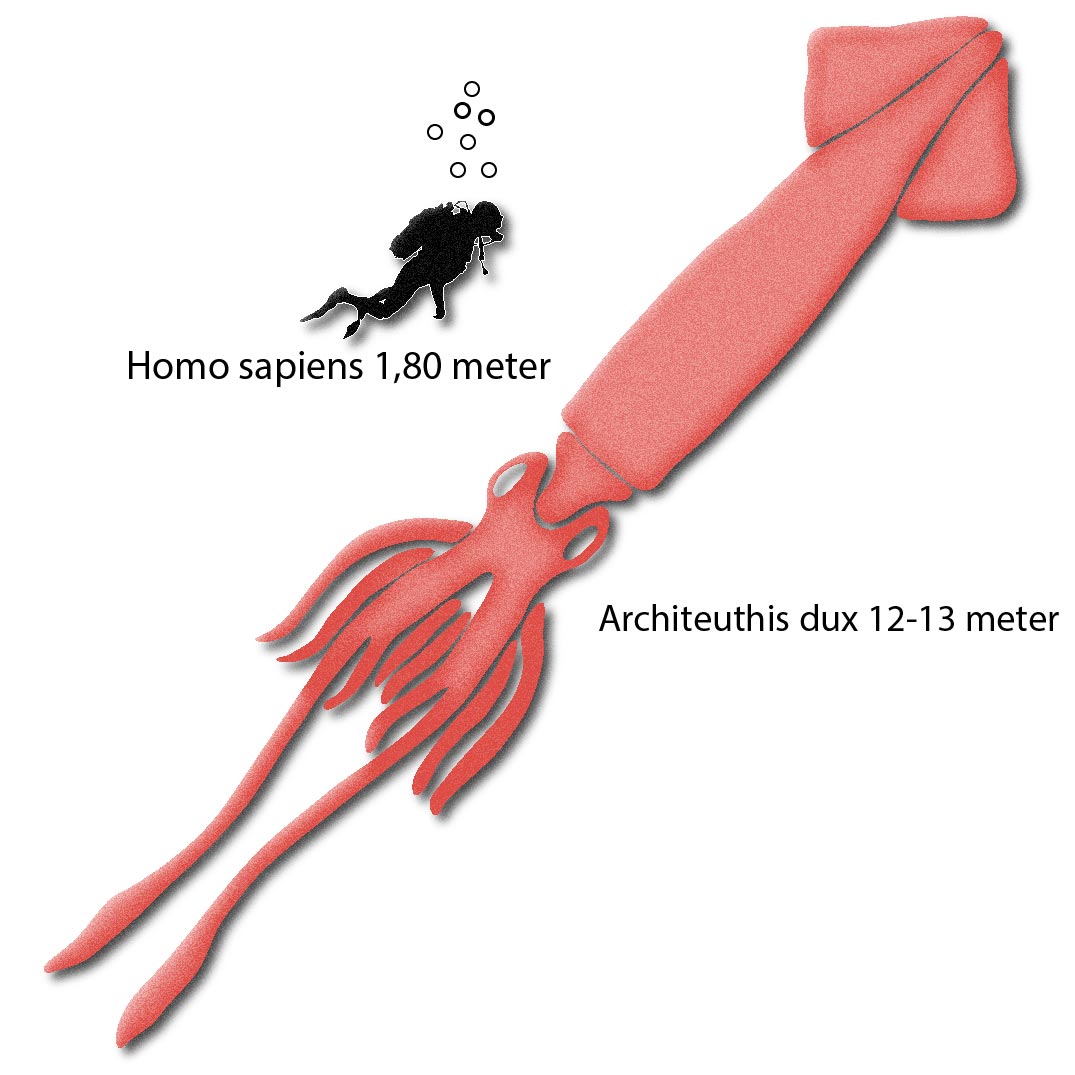
In 1857, the Danish naturalist Japetus Steenstrup linked the tell tales of ships being dragged to the ocean floor to the existence of the giant squid: A ten-armed invertebrate, that is credibly believed to grow up to 13 meters (43 feet) and weigh over 900 kg (2,000 lb).
Now, more than 160 years later, an international team of scientists have sequenced and annotated the genome of a giant squid.
‘These new results may unlock several pending evolutionary questions regarding this mantled species’, says the research leader, Associate Professor Rute da Fonseca from the Center for Macroecology, Evolution and Climate (CMEC) at the Globe Institute of the University of Copenhagen.
More data, more questions
Throughout the years only relatively few remains of giant squids – or, Architeuthis dux – have been collected around the world.
Using mitochondrial DNA sequences from such samples, researchers at the University of Copenhagen have previously confirmed that all giant squids belong to a single species.
‘However, our initial genetic analysis generated more questions than it answered,’ says Professor Tom Gilbert of the GLOBE Institute, who was part of the previous work on the giant creature.
“These new results may unlock several pending evolutionary questions regarding this mantled species.” Associate Professor Rute da Fonseca
Producing a high-quality genome assembly for the giant squid proved as challenging as spotting one of these animals in their natural environment.
This was, however, an important effort as the genome is the ultimate toolkit available to an organism.
Uncooperative samples
The challenges in the lab started with the fact that available samples originate from decomposing animals, usually preserved in formalin or ethanol at museums around the world.
This means that most of them cannot be used to obtain the high-quality DNA necessary for a good genome assembly.
“This project reminds us that there are a lot of species out there that require individually optimized laboratory and bioinformatics procedures.” Associate Professor Rute da Fonseca
Furthermore, elevated levels of ammonia and polysaccharides in the tissues were likely behind repeated failures in producing suitable libraries for nearly all available sequencing technologies.
‘This project reminds us that there are a lot of species out there that require individually optimized laboratory and bioinformatics procedures. An effort that is sometimes underestimated when designing single-pipeline approaches in large genome-sequencing consortia,’ says Rute da Fonseca, who started leading the project when working as an Assistant Professor at the Department of Biology in the University of Copenhagen.
A first step towards getting to know the giant
Despite the many challenges, the research group managed to get hold of a freshly frozen tissue sample of a giant squid collected by a fishing vessel near New Zealand. An incredible stroke of luck, according to the research leader.

Using this sample, the researchers were able to produce the currently best available cephalopod genome.
This ‘genomic draft’ provides a unique possibility to address many emerging questions of cephalopod genome evolution, the researchers behind the study explain.
By allowing the comparison of the giant squid with the genomes of better-known types of cephalopods, scientists now hope to discover more about the mysterious giant creatures – without necessarily having to catch or observe them in the depths of up to 1200 meters (4,000 feet) that they inhabit.
For example, the new genomic data might allow scientists to explore the genetic underpinnings of the giant squid’s size, growth rate, and age.
Read Revealed: The Mysterious, Legendary Giant Squid’s Genome for more on this research.
Reference: “A draft genome sequence of the elusive giant squid, Architeuthis dux” by Rute R da Fonseca, Alvarina Couto, Andre M Machado, Brona Brejova, Carolin B Albertin, Filipe Silva, Paul Gardner, Tobias Baril, Alex Hayward, Alexandre Campos, Ângela M Ribeiro, Inigo Barrio-Hernandez, Henk-Jan Hoving, Ricardo Tafur-Jimenez, Chong Chu, Barbara Frazão, Bent Petersen, Fernando Peñaloza, Francesco Musacchia, Graham C Alexander, Jr, Hugo Osório, Inger Winkelmann, Oleg Simakov, Simon Rasmussen, M Ziaur Rahman, Davide Pisani, Jakob Vinther, Erich Jarvis, Guojie Zhang, Jan M Strugnell, L Filipe C Castro, Olivier Fedrigo, Mateus Patricio, Qiye Li, Sara Rocha, Agostinho Antunes, Yufeng Wu, Bin Ma, Remo Sanges, Tomas Vinar, Blagoy Blagoev, Thomas Sicheritz-Ponten, Rasmus Nielsen and M Thomas P Gilbert, 16 January 2020, GigaScience.
DOI: 10.1093/gigascience/giz152
Aside from the University of Copenhagen (Denmark), the collaborating scientists come from several universities around the world.
The Villum Fonden, Marie Curie Actions, and the Portuguese Science Foundation (FCT) have supported the research project, among others.
Never miss a breakthrough: Join the SciTechDaily newsletter.
Follow us on Google and Google News.