We have a long history of yelling at our machines — cars that break down, televisions broadcasting our failing teams. But now, our machines understand us. And they’re talking back. They’re digging out recipes for us in the kitchen, navigating our car trips, finishing our sentences on Internet search engines, and translating foreign languages.
For that we have computational linguistics, also known as natural language processing (NLP), to thank. It’s one of the research focuses of Dragomir Radev, the A. Bartlett Giamatti Professor of Computer Science. It’s an area of study where computer science, linguistics, and artificial intelligence intersect, and it has become increasingly prominent in our lives, from Apple’s Siri to automated customer service.
In a nutshell, NLP is a means of training computers to understand human language. This is no easy thing. Human language is fluid; words change over time or with context. Take, for instance, the phrase “in a nutshell.” It could either mean “in a few words,” or “the edible kernel found inside the hard casing of a type of fruit.” Distinguishing these two very different meanings comes easily to us, but can be confounding to a computer. Natural languages are designed for the human mind – the wording can be imprecise, and still the meaning is clear. With formal languages — computer code for instance — every character needs to be in order or everything goes out of whack. NLP bridges that gap.
Radev’s work employs a number of computational techniques, including artificial neural networks, also known as deep learning. Essentially, computers learn to recognize complex patterns by being fed vast and wide-ranging amounts of data. Words, phrases, syntax, and grammar rules are assigned mathematical values. The idea isn’t new, but it picked up in the last couple of decades as digital data storage and computer processing power have increased dramatically. If you’ve used Google Translate recently, and noticed a boost in speed and accuracy of the results, that’s because the company switched to a neural network system.
Some argue that computers aren’t truly learning language since they’re not acquiring language the way humans do. Toddlers learn to speak not by poring over massive collections of texts but by engaging with the world around them with all five senses. The difference doesn’t concern Radev.
“It doesn’t affect how we do research because we’re not dealing with humans,” he said. “How we teach language to computers doesn’t have to be the same way humans understand language. When you build an airplane, you don’t say ‘Birds flap their wings, let’s build planes that flap their wings.’ That’s not how to do it, at least not in practice. We just want them to fly, whether their wings move or not.”
As one indication of the level of interest in these subjects, 132 students signed up for Radev’s NLP course last semester. Previously, he taught NLP to more than 10,000 students in a massive open online course (MOOC). This fall, he teaches a course on artificial intelligence, the study of teaching computers to perform tasks that would be considered intelligent when humans do them. The course covers logic, learning, and reasoning. It includes challenging assignments that ask the students to build systems that can play two-player games like Othello and Go, solve mazes, simulate autonomous car driving, translate texts using neural networks, and learn from interacting with the environment. This is now the largest class in the Computer Science department, with more than 200 enrolled students this semester.
With another project, AAN (All About NLP), Radev is also helping those interested in NLP navigate their way through the increasing body of research on the subject. He and his students from the LILY lab (Language, Information, and Learning at Yale) have collected more than 25,000 papers and more than 3,000 tutorials, surveys, presentations, code libraries, and lectures on NLP and computational linguistics. The ultimate goal is to use NLP to automatically generate educational resources for those seeking it, and to steer them in the right direction. It includes single-paper summaries, multi-source descriptions of algorithms, research topic surveys, and user recommendations for teaching resources.
Teaching Humor to Computers
Computers can figure out how the galaxies formed, sift through unimaginable amounts of data and calculate a prime number of more than 17 million digits. But can they tell a joke? Probably not for a while, Radev said, but he’s still going to try.
As part of an ongoing project, Radev has been working with Robert Mankoff, the recently retired cartoons editor for the New Yorker. Specifically, they’ve focused on the magazine’s weekly caption contest in which readers submit captions to a cartoonist’s illustration. The caption judged the funniest wins.
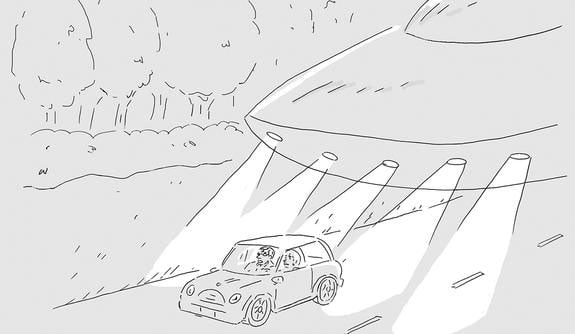
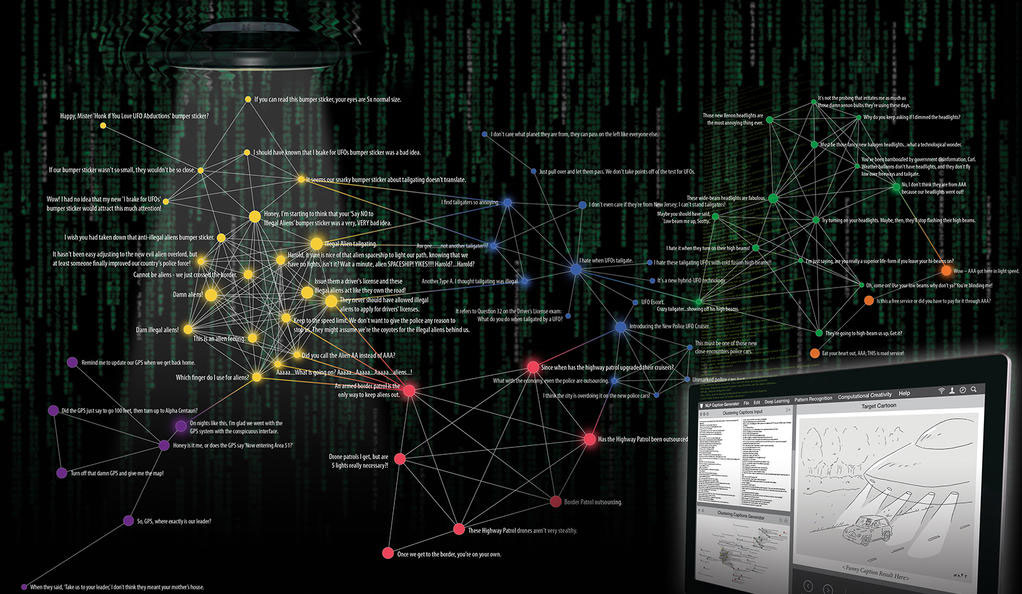
The magazine receives thousands of submissions every week from would-be cartoonists. The editors then winnow those down to three finalists, to be judged by New Yorker readers. It’s an arduous process that perhaps could be made easier with the help of NLP. Radev explains that each contest inspires multiple submissions based on the same idea. One illustration, for instance, might inspire many submissions with a similar play on words regarding a horse standing at a bar. A bartending goose serving the horse in the same picture, meanwhile, begets a different batch of closely-related jokes.
Radev, Mankoff, and collaborators at Columbia University and Yahoo Labs have designed a program that intends to identify themes in the submitted captions.
“The purpose is so that the editors don’t have to read through 5,000 submissions every week,” Radev said. “If 100 are all the same joke, they could read just one or two. If the basic idea is funny, then they can dig in deeper and pick out specific ones. If it’s not funny, they can just skip the whole cluster.”
Branching off from that is a project in which computers would generate their own funny captions. One early stumbling block they encountered was that, while computers have gotten very good at picking out objects in photos, illustrations still give them a lot of trouble. To get around that, he and his students described the images of about 500 cartoons in a language that the program can recognize.
“Now, it might be much easier to come up with new jokes by looking at descriptions of the cartoons and at the submissions already made — because that’s a good starting point,” he said. “We could combine two captions into one, or modify an existing caption by adding a few words to make it sound funnier.”
It’s a particularly tricky challenge. So far, computers have bested humans at chess, the ancient game of Go, and even the trivia show Jeopardy. But humor is a uniquely human trait and Radev doesn’t expect that the result will put any cartoonists out of a job anytime soon (nor, for that matter, does he think automated translators will replace their human counterparts). “It may or may not work, but it will be very interesting to be able to see if a computer can understand New Yorker cartoons and get the jokes,” he said.
Radev is interested in what’s known as computational creativity. It’s what would allow programs such as Watson, Siri, and Alexa to not only provide correct answers, but even display a bit of personality. There are already attempts to make our devices a little chummier. Siri, for example, occasionally gives some gentle snark: Q: “Siri, what’s the meaning of life?” A: “42” (a reference to the classic book “The Hitchhiker’s Guide to the Galaxy”).
“But it doesn’t really have a sense of humor – that’s pre-programmed by the humans,” Radev said. “It would be interesting in the future to come up with systems that actually can understand and generate funny text.”
Coaching the Next Generation of Computational Linguists
Radev, who grew up in Bulgaria, is fluent in several languages. “I like how similar, yet how different languages are,” he said. “And the fact that there are rules, but the rules aren’t strict, which makes it more interesting. I don’t like pure math because things are too strict. Languages are somewhere right in the middle.”
In 2006, Radev co-founded the North American Computational Linguistics Olympiad (NACLO), an annual competition that brings together middle and high school students from across the U.S. Besides identifying students with talent in linguistics, it also introduces them to the field of computational linguistics.
NACLO has had more than 20,000 student participants. Unlike many other high school events related to computer science, almost 50% of the participants in NACLO are female. The top finalists go on to compete in the International Linguistics Olympiad. This year’s NACLO (hosted at 200 sites throughout the U.S., including Yale) sent eight participants to the international competition in Dublin in August.
NACLO participants are given a series of problems drawn from a variety of languages to solve, usually involving translation. Some call for traditional linguistics methods, and others call for computation to arrive at the solutions. Logic and reasoning are the only skills contestants need. Radev said he and the other organizers recognize that linguistics is rarely taught in high schools, so the problems are set up in a way that no prior knowledge of particular languages or linguistics is required.
Problems are often based around relatively obscure languages. For example, one set of sentences might be written in Taa — spoken by about 2,600 people in Botswana and Namibia — each followed by an English translation. Based on the patterns they could deduce from these sentences, the students then must translate the next set of Taa sentences with no accompanying English translations.
“We use charts so it’s easier for the high school students to understand,” said Radev, who in 2015 was named a Fellow of the Association for Computing Machinery, one of the highest honors in computer science. “‘This is the semantic presentation of this word, this word, that word,’ and then you have to figure out how this method works and translate some additional words into those presentations.”
Tom McCoy, who graduated from Yale this year with a major in linguistics, began competing in NACLO when he was a high school student living in Pittsburgh. He knew nothing of computational linguistics at the time, but he liked puzzles and breaking codes, and his sister suggested that he give the competition a try. Radev was one of his coaches.
“He was really great,” McCoy said. “I think the best phrase to describe him is ‘a force of nature.’ He just does so many things and does them all very well. He’s the very active professor/researcher, but then he also manages to give so much time to the Olympiad.”
McCoy was committed to studying biology before joining NACLO, which sent him on a different course. This fall, he entered the prestigious Ph.D. program in cognitive science at Johns Hopkins with a focus on computational linguistics.
Radev recruited students for his LILY lab shortly after coming to Yale in January 2017. He quickly assembled a team of Yale students to work on a neural network system for summarizing sets of related news articles. The resulting paper, whose first author is Michihiro Yasunaga, YC’19, was accepted for presentation at the prestigious Conference on Computational Natural Language Learning in Vancouver in August. The LILY (Language, Information, and Learning lab at Yale) lab, led by Radev, now includes six Ph.D. students and more than a dozen Yale undergraduates. The LILY team is working on a number of new papers on survey generation, medical document understanding, cross-lingual information retrieval, and dialogue systems.
Collaborations
NLP is a field of study that lends itself well to cross-disciplinary collaborations, and Radev hasn’t wasted any time. Even before he arrived at Yale in January, Radev was in contact with several faculty members from other fields about striking up collaborations, including those from the medical school, the humanities, and the social science programs.
“There’s a general awareness now that natural language processing and these other tools can be helpful to those other fields,” he said. “Ten years ago, many people from other fields didn’t even know that you could do this sort of work. If we collaborate with people in political science or medicine, they get something out of it because now they can analyze data in ways they couldn’t before. And computer science people get something out of it with interesting data sets to work with for their theories.”
Political scientists could use the technology, for example, to analyze the speech and texts of elected officials. An objective analysis of strategies and rhetoric in a debate, for instance, could help discern whether a candidate appealed to nationalism or concerns about the economy. How often was name-calling used as a debating tactic? Lincoln Swaine-Moore, one of Radev’s students, analyzed last semester connections between the speech of officials and contributors to their campaigns.
“For example, if a senator gets a certain amount of funding from the pharmaceutical industry, does that mean they’ll talk more about pharm issues in their speeches?”
The fields of healthcare and medicine also stand to benefit greatly from natural language processing.
“Another possibility is to see if there is any bias in letters of recommendation to medical schools,” he said. “There are studies that show women who apply for certain jobs are treated differently. People interrupt them more frequently, or they perceive a certain trait of the person in a negative way – they might use the word ‘fiery,’ whereas a man would be described with a gentler word.”
He has also talked with Yale School of Medicine professor Harlan Krumholz about possible collaborations. Krumholz, the Harold H. Hines Jr. Professor of Medicine, director of the Yale Open Data Access Project, and faculty co-director of the Yale Center for Research Computing, said nurses’ notes, radiology reports, and so many other documents have created a mountain of unstructured data in medicine. Radev’s expertise could help make sense of it all. As an example, he points to forms that force patients to grade their symptoms on a scale of 1 to 5.
“We give them five options, but the truth is that they have to tell me a story for me to understand how they feel,” Krumholz said. “The holy grail is figuring out how to take the largely undisciplined data that exists everywhere in medicine and turn it into something that can spark new knowledge and insights and better care.”
Doing that means getting away from a system that requires people to talk and think like computers. Instead, he said, we need computers to come up with insights from the way people naturally communicate. It’s an ambition that, not long ago, might have seemed out of reach. With the work of people like Radev, it’s starting to happen.
“That’s why I immediately thought he would be such a great addition here, and why I looked for ways to work with him,” Krumholz said. “He’s a spectacular addition to our faculty and gives us more world-class expertise. When someone like that arrives on campus, you are immediately drawn to try to see if there are opportunities for collaboration.”
Never miss a breakthrough: Join the SciTechDaily newsletter.
Follow us on Google and Google News.
1 Comment
… it is more easy to teach AI the Humor, than to physicist or intelligence, because they are humor proof…